

目次
データベースの正規化
データベースの正規化とは
関係データベースの正規化とは、データの重複をなくし整合的にデータを取り扱えるようにデータベースを設計することです。
データの一貫性を維持し、効率的なデータアクセスを可能にします。
関係データベースとは、次のようにデータを表の形で管理するデータベースのことで、テーブル(表)は、レコード(行)とカラム(列)によって形成されています。
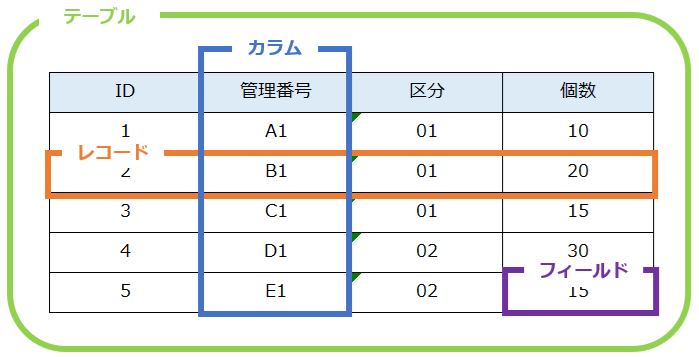
このテーブルで管理されたデータの整合性を確保するために正規化をおこないます。正規化することで、データの冗長性と不整合が起きる機会を減らすことができます。
スポンサーリンク
正規化の手順
データベースの正規化には、第1正規形~第5正規形、およびボイスコッド正規形などの種類がありますが、第1正規形~第3正規形までで、十分に正規化されたと考えることも多いです。

正規化前(非正規形)
例えば、次のような注文があるとします。
鈴木一郎:A商品を1つとB商品を2つ注文
佐藤次郎:C商品を1つ注文
田中三郎:D商品を2つ、E商品を1つ、F商品を1つ
上記の注文をそのまま表に挿入すると次の通りです。各行の長さがバラバラで商品が繰り返されている状態です。
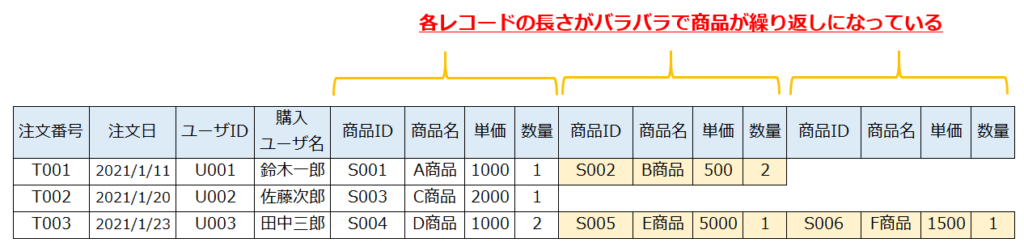
【第1正規形】繰り返しを整理
データベースでは、レコード単位でデータを扱うため、正規化前のようなデータはデータベースのテーブルに格納することすらできません。
まずは、繰り返し項目のそれぞれを別レコードとして独立させ、各レコードの長さを整えます。(正規化前は、各レコードの長さがバラバラで商品が繰り返されている状態)
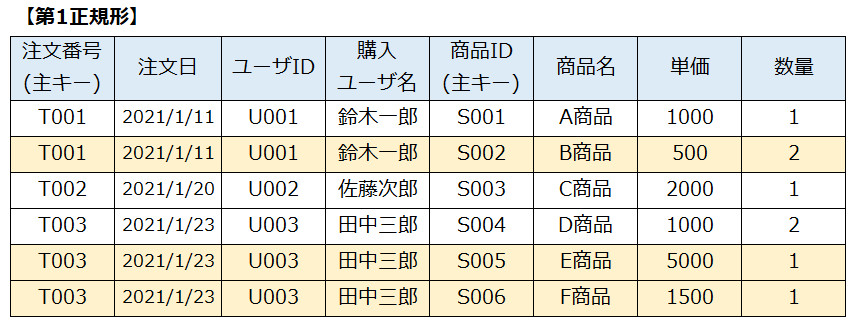
上記が「第1正規形」のテーブル(表)です。背景色がついているレコード(行)が、正規化前では繰り返し項目になっていた部分です。
繰り返し項目を別レコードとして独立させることで、すべてのデータをテーブルに格納できました。
【第2正規形】部分関数従属している列を整理
第2正規形では、部分関数従属している列を整理します。

例えば、第1正規形で作られたテーブル(表)の主キーは「注文番号」と「商品ID」です。
「注文番号」と「商品ID」が決まれば、レコード(行)を一意に特定できますが、実は「注文番号」が決まるだけで「注文日」「ユーザID」「購入ユーザ名」は特定できます。このような状態が部分関数従属です。
そして、第1正規形のテーブル(表)から、部分関数従属しているカラム(列)を切り出したものが「第2正規形」です。
次のテーブル(表)は部分関数従属のイメージ例です。
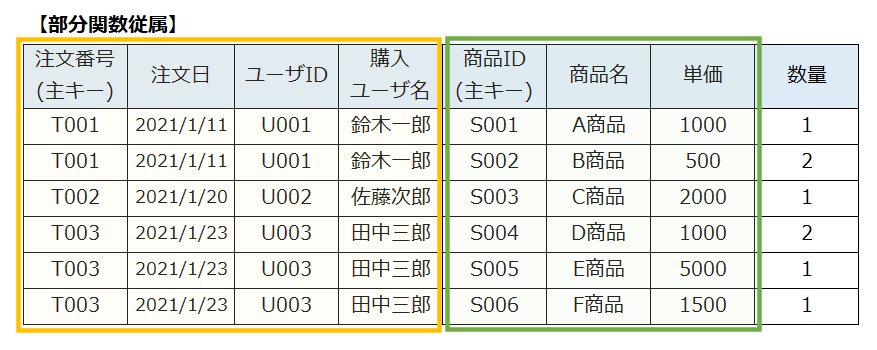
オレンジ枠の部分は「注文番号」が決まれば特定できる項目、緑枠の部分は「商品ID」が決まれば特定できる項目です。
下記が「第2正規形」のテーブル(表)です。
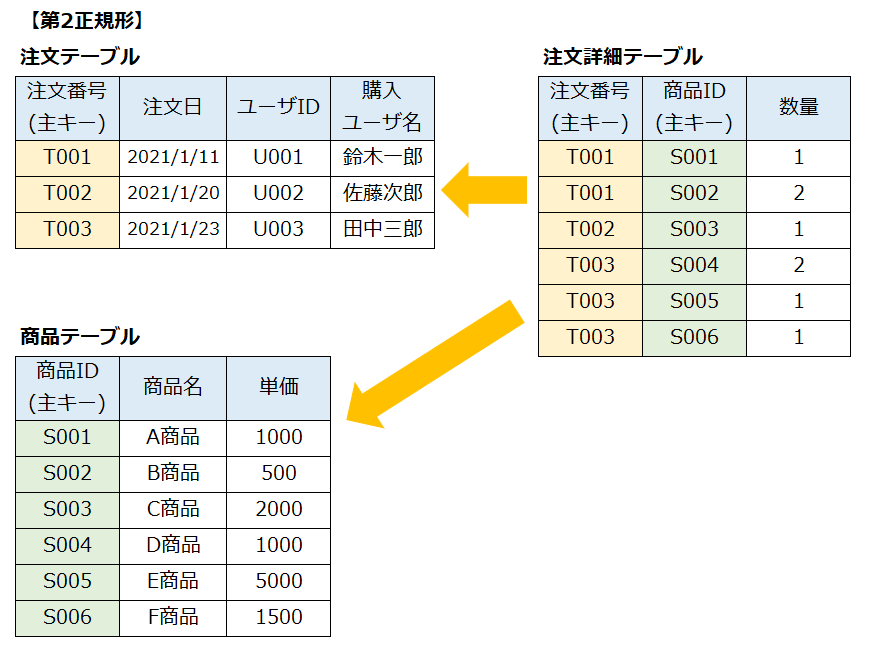
オレンジ枠で囲んだ部分を「注文テーブル」、緑枠で囲んだ部分を「商品テーブル」として切り出しています。そして残った部分を「注文詳細テーブル」として3つのテーブル(表)に分けています。
【第3正規形】関数従属している列を整理
第3正規形では、主キー以外の列に関数従属している列を整理します。関数従属とは「○○が決まれば特定できる項目」のことです。
第2正規形の「注文テーブル」は「注文番号」が主キーです。そのため「注文番号」が決まればレコード(行)を一意に特定できます。
しかし、よく見ると「注文番号」以外の列に関数従属している項目があります。それは「購入ユーザ名」です。「購入ユーザ名」は、「ユーザID」が決まれば特定できる項目です。
次のテーブル(表)は関数従属のイメージ例です。
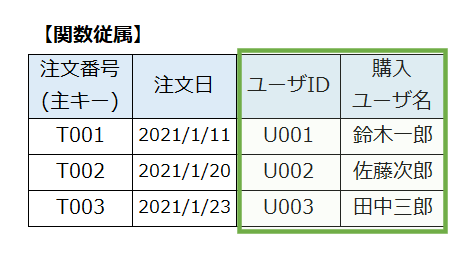
緑枠の部分は主キー以外である「ユーザID」が決まれば特定できる項目です。このように、第3正規形では、主キー以外の列に関数従属している列を整理します。
下記が「第3正規形」のテーブル(表)です。
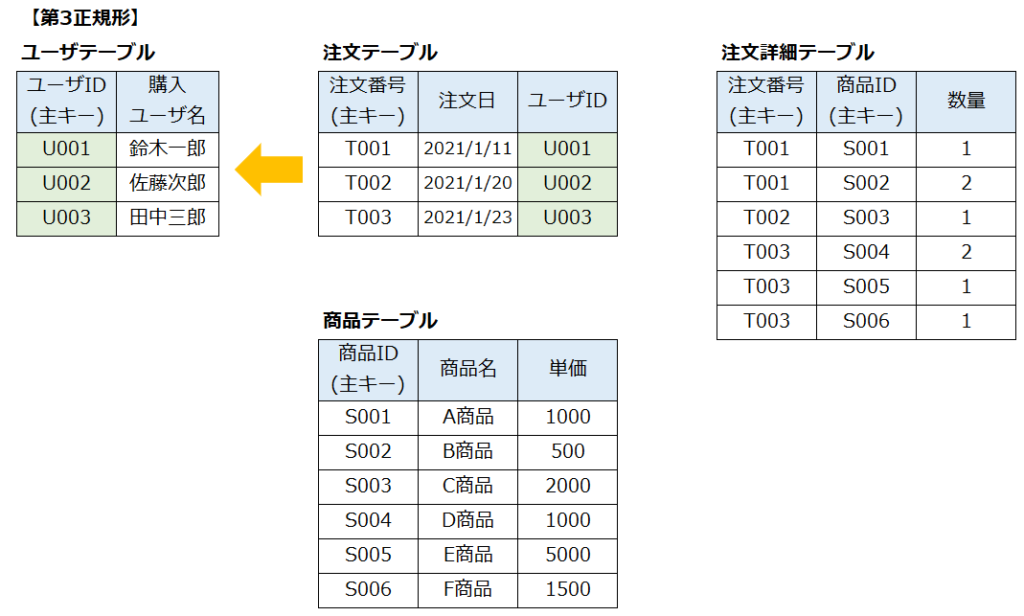
緑枠で囲んだ部分を「ユーザテーブル」として切り出しています。